Autonomous Product Development
In a routine customer call, a user complained that the text on a button was too technical. Our AI COO had listened to the call and created the task in Linear. Our AI Engineer then shipped the fix.
None of our product team had listened to the call or even been aware of the customer request. A customer simply mentioned it. The app improved. All our other customers benefitted.
This is the Customer-to-Customer Feedback Loop in motion.
At Versey we’ve just started Autonomous Product Development, allowing improvements to be planned and implemented without humans in the loop.
This started as a small open-source side project, but we quickly found that when we needed a little engineering support for routine bugs and maintenance, it was worth deploying into our core app.
The goal is to create a cycle where the interactions with one user ultimately improve the app for everyone - in other words, a Customer-to-Customer Feedback Loop.
Once you achieve a Customer-to-Customer Feedback Loop, your product gets better simply because people are using it in a classic flywheel. It also frees up our team to focus on meaningful projects.
This is a very early “research preview” as the cool kids would call it - just an “n=1” and over a short time horizon. There are potential security and cost footguns as shared below. I hope this inspires you to experiment with an Autonomous Product Development loop in your own companies.
I’ll share:
- Our results so far
- How this is set up
- Mishaps and pitfalls - including spending $2400 overnight the first time we turned it on
- What it takes to get here for most other organisations
Customer results
Let’s start by grounding this in how it’s actually helping real customers.
Our startup Versey provides a freemium app for AI-supported writing.
It helps experienced writers finish, on average, around twice as fast. It does this by making editing and getting feedback effortless, bringing the tasks writers usually turn to LLMs for right into the editor.

It’s a real product with real, paying users.
“I’m pretty fast - I can turn out an article in an hour. But now I can do it in half an hour. I don’t give a lot of glowing reviews, but I haven’t been this excited by a technology tool since email.”
Tracey Borrenson, Marketing Advisor and Director at Partnerships & Alliances, and Co-Founder of Ecosystem Research.
“It’s addictive… […] The highlighting, the in-line chat - all pretty extraordinary. It was very helpful for tomorrow’s edition!”
Marcus Lawrence, Editor of Zinstrel, and SIQA Creative Advisory Council member.
A few weeks ago, we realized we might need to hire a new junior engineer to handle a growing number of low-value tasks. We didn’t have the budget. However, recently I had built an open-source side project - an autonomous AI engineer which monitors its environment, creating tasks or receiving them from the team, then building and deploying them to production.
Instead of hiring, we decided to set up the AI Engineer.
Within the first hour of turning it on, it had already shipped around a half dozen fixes and improvements.
A few improvements the engineer added:
- If the AI thinks of a suggested rephrasing to go along with any feedback, show the suggestion below the feedback instead of making the user click “preview suggestion”
- Give the different chats for a given document names so selecting between them is easier
- Add a preview of font sizes on the settings page where this can be controlled
Other tasks included a handful of bug fixes and some genuinely helpful refactors.
But as mentioned the real magic happened when the AI Engineer started pairing up with our AI Chief Operating Officer - an OpenClaw which manages the company’s central data layer - to listen to customer calls and create tickets from them.
Why most customer signal dies
Customer feedback is traditionally passed from the customer success team through to a product owner, who also monitors product analytics, and who may then create tasks for designers and engineers to build.
Having done this the traditional way in startups and larger enterprises, I’d say the fully-loaded cost for even a small improvement is around $500, with a turn-around of days to weeks. With agents that’s down to ~$100, but there is a minimum floor.
Most customer signal goes to waste:
- Only a fraction of customer issues are reported or observed
- Only a fraction of those get turned into tickets by the Product Owner
- Only a fraction of those get prioritised on the development road map - most die in the backlog.
Because time is finite, only a fraction of problems can be solved. Product teams should spend their time “lifting heavy rocks” on projects that will meaningfully improve the company. You shouldn’t hire top engineers and then have them working on trivial optimisations.
With all the human overhead, there’s a long tail of work that never gets touched.
Here’s the new system:
- Observability brings that implicit and explicit customer signal to the product team
- Autonomous AI Engineers pick up these tasks and build
- Autonomous Review agents review the code
- Autonomous AI Engineers push to production so that other customers can benefit.
Non-urgent tickets wait 24 hours before being implemented, meaning a human can periodically review what’s in the list, adjusting and deleting tickets as needed.
Changes are reported in Slack, allowing an engineer or designer to review as needed. All tickets are easily reversible.
Finally, the system is self-learning: it reviews itself each day and listens to human feedback, for example upgrading its models to the latest versions or updating its system prompt to escalate particular types of task to a human for review.
Getting this set up
I’m going to go into granular detail about how we implemented this. This is really designed for an engineer looking to do the same thing. Skip to the section on Team & transformation if you are non-technical but would like some tips on navigating this with the team.
The areas to set up are:
- Observability
- Product
- Engineering
- Team & transformation
Observability
What can the AI see?
90% of the effort should go into passive tracking. The tools we use are in brackets. Anonymise everything to keep specific user actions and data private.
- Error catching, tracing (Sentry): every glitch should be caught and reported.
- Product analytics (Posthog): funnel, success of core Jobs To Be Done flows, per-feature usage.
- LLM analytics (Posthog): Categorise intents and identify success and latency of each response. Failure can be identified by users rephrasing their original question, not taking any suggested action (in our app - accepting an edit), and so on. User inputs are anonymised and obfuscated before any analysis for privacy reasons.
- Server logs (Vercel): errors and anomalies surfaced from production
- Application monitoring (Sentry): Per-endpoint latency
- Codebase itself (Github): Monitoring for opportunities to refactor or simplify
- Internal comms (Slack) & any customer-facing surfaces
For direct user feedback, don’t rely on customers using the helpdesk. Reach out, build genuine relationships, check in pro-actively. When I was in peak “building” mode with Versey I was still taking 3 - 4 calls per day with customers. Ask customers to share their screen and walk you through. Call transcripts and recordings are the richest source of feedback.
Product
How do tasks get created?
Humans should be focused on big, needle-moving projects - not writing up incremental changes. The AI product function monitors observability (both passive and direct feedback) and writes up potential improvements.
For us, two systems create tasks:
- An autonomous Chief Operating Officer (OpenClaw), which is part of our central company data layer, reads internal and customer call transcripts and customer feedback.
- An autonomous AI engineer (Anthropic’s Managed Agents) monitors observability and creates feature tickets.
Tickets are stored in Linear. This also acts as a control plane and place to add your own tickets. We can also send tickets directly to the engineer from Slack.
Managing Signal:Noise. In the human-centric product function, you might wait for at least two customers to report the same issue or feature before you action it for the engineering team. However, changes are free in an AI-centric function, so take an opt-out approach: every signal becomes a ticket, and product can prune tickets or undo releases later.
Engineering
How do tasks get shipped?
Our autonomous AI engineer uses Anthropic’s much underutilised Managed Agents.
This runs a serverless, file-system backed instance of Claude Code. It downloads the latest version of the codebase and can create large, complex changes. Because it’s serverless, you can spin up as many as you need, and there is no additional cost for the service above the base inference cost of the AI.
Every 30 minutes the agent reviews all observability (as described earlier) and picks up tickets from Linear.
Change verifiability - has the AI actually done the task on the ticket that it thinks it has? Automated tests and evals can be gamed by LLMs, even with good prompt engineering.
The agent should test the happy and sad paths in a preview environment, and save screenshots and videos of the work into the PR. This is hard to game, and the agent will fix issues if the screenshots don’t show the expected change. This can be tricky to set up with Claude Managed agents - our approach has been to deploy draft PRs to a Vercel preview environment first.
A separate review agent spins up to review PRs. The fresh context means it carries none of the prior assumptions of the engineer. If after 3 rounds of review the PR has not been merged, issues are escalated to a human.
LLMs are excellent at review and can review the screenshots too - meaning it’s hard to get a bad PR through this system. We set up evals to red-team this all the same.
Anything the agent has access to it will eventually attempt to do - this is the agent version of the infinite monkeys typing out the works of Shakespeare. If you give the agent read-access to production data, it will leak that data in a PR. If you give it access to anything billing or infrastructure related, it will run up the card. Don’t design a system you wouldn’t feel comfortable running overnight.
Regressions should be picked up fairly quickly and are fixed automatically provided you have done the foundational observability work. In practice, we haven’t seen this happen.
Use self-learning instead of manual context engineering. After every ticket is shipped or cancelled, new learnings are stored in memory. Once a day, an agent does a retro where it reviews all new learnings and all AI traces across different sessions, and consolidates the memory.
Team & transformation
How does this change how we work?
Navigating this is as much about people as the system. Our team at Versey is AI-positive, but I know plenty of engineers who are more cautious - so here’s our thinking.
The job changes more than it shrinks. I’m not a fan of downsizing if talented people can be redeployed, and the honest framing for the team is simple: growth is everyone’s responsibility, and the only one who can fire all of us is the customer if we fail to innovate fast enough. We will automate the lower-value work so we can focus on meaningful projects - which means everyone picks up new management and customer-facing skills.
Managing a team of highly productive agents surfaces the same two failure modes as managing people: being out of touch, and failing to trust and develop them.
Out of touch. You can only assign work well if you know what agents are good and bad at, and the only way to learn that is to ship with them yourself (budget ~$5–10k of token spend per manager to build the intuition).
More often, managers are out of touch with customers. Every role becomes more customer-facing - in Versey’s early days one of us was cold-DMing and setting up calls for developers for four hours a day - and that direct signal is exactly what feeds the loop.
Trust and develop. Give agents latitude to work and make mistakes without micromanagement, the same way you’d grow a junior. You don’t “prompt engineer” them; you give clear feedback when you close a ticket and they update their memory.
Stop treating each agent as a tool whose every mistake reflects on you. They’re probabilistic - in a given hour one might produce eight good changes, one great one, and one bad one. Net-net you’re up, even before you roll the bad one back. Even if you don’t roll it back at all.
And above all: this is comparable to working with a human. Self-driving cars only need to be better than human drivers to improve road safety.
Focus on the big projects. Keep half an eye on the agents.
Let’s discuss some objections to this:
Regulation & Quality assurance: SOC 2, ISO 27001, ISO 42001, ISO 13485, the GxP cluster: (GxP / automated CSA, EU GMP Annex 11, 21 CFR Part 11) all require that a human reviews PRs before they go live. If you’re in a regulated domain, keep the human gate; everything here still applies behind it.
In my experience the AI reviewer is better at picking up issues than a human, but regulation is always going to be a step behind, and quality certifications are fundamentally to align your processes with your customer’s risk appetite rather than your own.
Fear of slop. Many engineers have had poor experiences with previous generations of LLMs, and a clean codebase - especially on core modules - matters. Several popular developer influencers have an anti-slop stance that doesn’t match the quality of code I’m seeing from LLMs. Sadly, all too many smart engineers would rather borrow their opinions from others than find out for themselves.
If your engineers are not predominantly using agents to code, then get them to ship $5k - $10k of tokens’ worth of features first as this is simply a lack of familiarity.
If your team does have that experience, adjust the parameters in the reviewing agent for which PRs require human escalation. Don’t let perfection be the enemy of progress. Avoid limiting where agents can work, e.g. to “leaf” work (e.g. code without downstream callers, like the leaves on the branches of a tree.) Some of the best agent-suggested-and-implemented refactors for us have been on core functionality.
Design & taste arguments - “What if it ships things that don’t meet our bar for design?” Great design is all about trade-offs, restraint, and in many situations, good taste - but with a little experimentation these things can be encoded with good context. Here’s a great example by designer Tommy Geoco.
What I’ve found in practice is that AI is fantastic at the “customer feedback -> incremental fix” loop and the “product analytics -> incremental feature” loop. These marginal gains are the product: design is how it works. They’re also just boring for any actual designer to solve.
The features it ships also make brilliant prototypes. It’s shipped ideas that I’d considered but ruled out and found I liked them better as a user. A couple of features I’ve unshipped, and a couple I’ve liked but tweaked.
It can be hard to let go as a designer - this thing feels like your portfolio, your vision. The truth is many users just want functionality, not a concept car. Notion has great design but it also ships relentlessly. The best teams don’t gatekeep design, they let everyone ship.
Deployment
The pathway to deployment is: Inspiration, Functioning Demo, Low-stakes deployment. As with all org changes, recruit allies before you announce sweeping changes and projects that could make people feel anxious about their job security.
Here’s how it played out for us:
- Inspiration: an Anthropic Code with Claude conference where I was able to see demos of Self-Learning and Long Horizon agents (agents pulling from a task board). I was familiar with Anthropic’s Managed Agents but hadn’t quite clocked how powerful they were until the conference.
- Functional demo: one bank holiday Monday I built an open-source self-managing-codebase with the AI Engineer in it. If you are a Type-A executive, making time for innovation spikes like this will feel like a distraction from your current goals, but this is where the real breakthroughs come. Chess Grandmaster Joshua Waitzkin once remarked that one of the mistakes he made in his training strategy was being overly focussed on likely-to-occur board positions - the best insights came from exploring broadly.
- Low-stakes deployment: we had no plans to deploy this in our product Versey, but a few days later we found ourselves wondering if we should hire another junior developer to handle distracting, low-level work. Following Shopify’s internal rule “Don’t hire until you’ve tried AI”, I set up the AI engineer instead. The Versey product is also in a place where I was satisfied that the possible downside was acceptable.
If you’re still unsure, think probabilistically about the relative upside (cheap, near-unlimited junior development work once you add in spend controls) versus a reversible and capped downside, which at least in our “n of 1” case in practice hasn’t manifested.
Second, baseline your fault tolerance against actual humans, not perfection. To err is human; to forgive, divine.
If you’re still struggling with loss aversion, read Software Has Bugs. This Is Normal by DHH. For me it was like a Zen Koan that, when I finally understood it, helped me build significantly better products.
Going live
Logic be damned: the first night that I left the agents shipping overnight, I was up until 2am wracked with anxiety.
Come morning the app was fine. Then our finance guy pinged me: the agent had burned through $2400 of tokens! My implementation was using the most expensive Claude model for all sorts of trivial tasks such as gathering observability data and driving the browser to get screenshots. Such is the cost of progress.
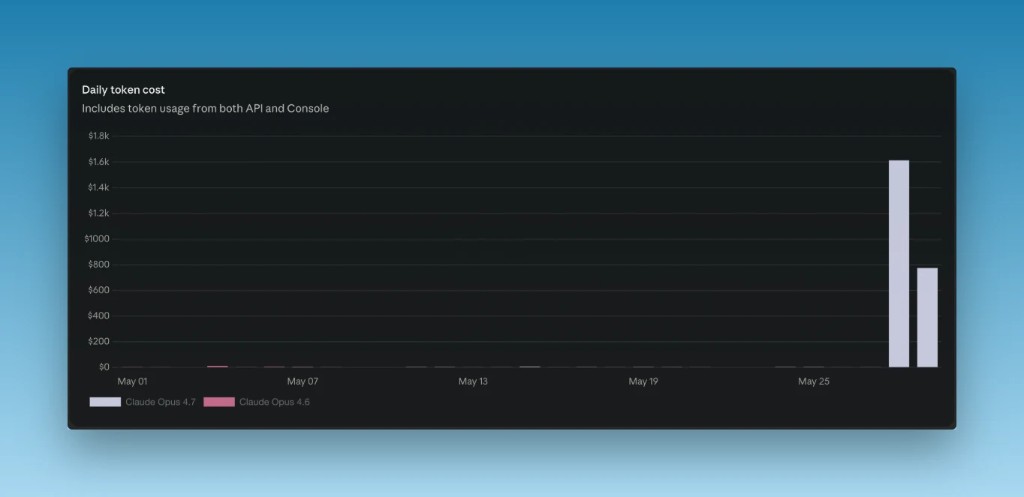
Set up spend controls, and as we’ve done, add a triage system that routes different requests to different models depending on the requirement.